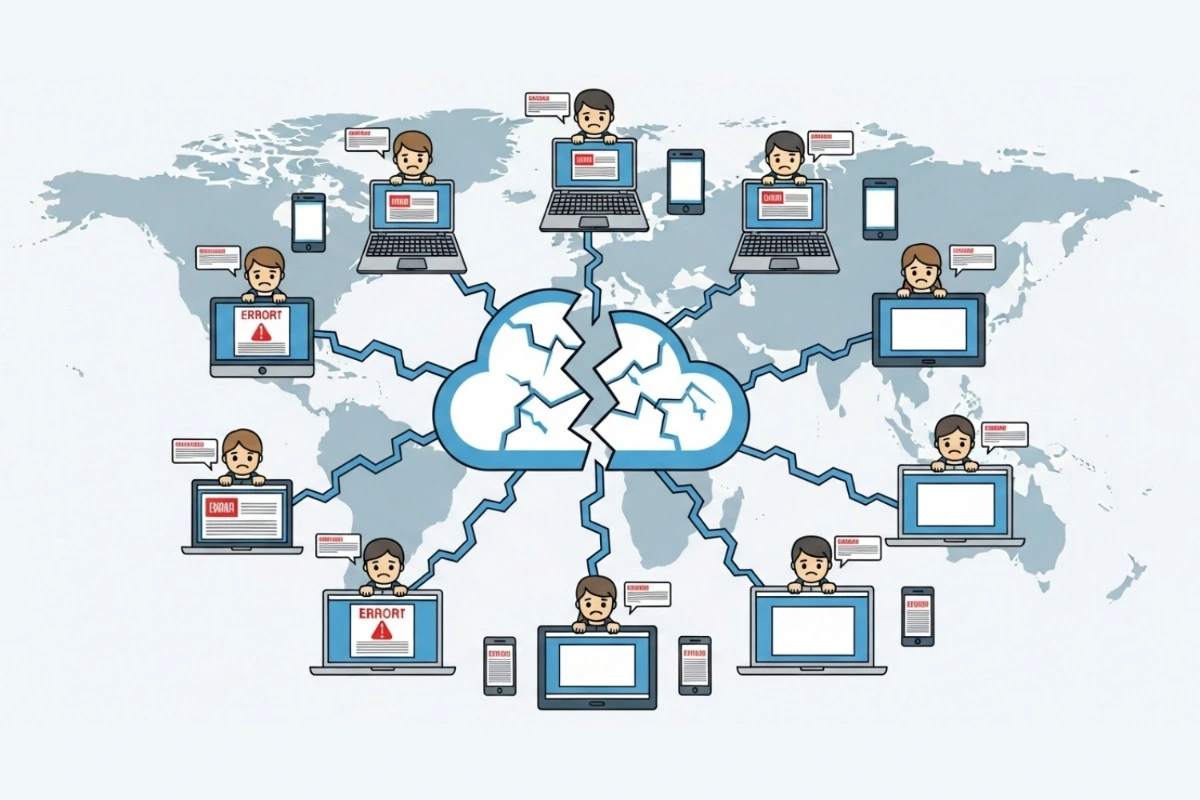
No dia 20 de outubro de 2025, uma grande falha na Amazon Web Services (AWS) expôs novamente a fragilidade da infraestrutura digital que sustenta o mundo moderno. Quando o maior provedor de nuvem do planeta enfrenta uma interrupção, o efeito cascata se espalha em minutos — derrubando aplicativos, sites e plataformas usadas por bilhões de pessoas.
De mensageiros criptografados a serviços financeiros, o incidente demonstrou como a dependência de poucos provedores transforma uma simples falha técnica em um evento de impacto global. Neste artigo, analisamos as causas, consequências e as lições estratégicas da mais recente pane da AWS — um alerta para empresas, profissionais e usuários sobre a importância da resiliência digital.
A espinha dorsal da internet moderna
A Amazon Web Services é o maior provedor de serviços em nuvem do mundo, com cerca de 30% do market share global. Ela oferece computação, armazenamento e ferramentas para milhões de empresas, governos e desenvolvedores. Sua região US-EAST-1, na Virgínia do Norte, é especialmente crítica — concentrando parte vital da infraestrutura da internet.
Dependência e vulnerabilidade global
Milhões de aplicativos dependem da AWS. Quando ela falha, o mundo inteiro sente: redes sociais, bancos, lojas virtuais e até dispositivos domésticos inteligentes ficam fora do ar. Essa centralização — dominada por AWS, Microsoft Azure e Google Cloud — cria verdadeiros pontos únicos de falha globais.
Histórico de interrupções
Falhas importantes já ocorreram em 2020, 2021 e 2023, quase sempre na mesma região (US-EAST-1). Cada uma resultou em prejuízos de bilhões de dólares, pressionando o setor a investir em redundância e estratégias multi-cloud.
Quadro-resumo do incidente (20/10/2025)
| Fator | Detalhes |
|---|---|
| Data e hora | 20 de outubro de 2025, às 3h11 (ET) |
| Região afetada | US-EAST-1 (Virgínia do Norte, EUA) |
| Serviços impactados | EC2, S3, Lambda, Route 53, entre outros |
| Principais afetados | Signal, Snapchat, Zoom, Disney+, Fortnite, Coinbase, Alexa |
| Causa técnica | Falha na rede interna do EC2 ligada ao DNS |
| Duração total | ~9 horas |
| Custo estimado global | US$ 1,8 a 2,3 bilhões |
| Status atual | Totalmente restaurado às 12h (ET) |
Impacto global: comunicação, jogos e finanças
- Comunicação e mídia — Signal, WhatsApp e Zoom ficaram fora do ar por horas, afetando reuniões e comunicações seguras.
- Entretenimento e jogos — Fortnite, Roblox e Disney+ ficaram inacessíveis, afetando milhões de usuários simultaneamente.
- Setores críticos — Plataformas como Coinbase e Robinhood enfrentaram atrasos em transações, enquanto sistemas de companhias aéreas e órgãos governamentais registraram instabilidade.
Até dispositivos da Amazon, como Ring e Alexa, ficaram inoperantes, expondo vulnerabilidades em ambientes IoT domésticos.
Causas técnicas e resposta da AWS
A origem do incidente está relacionada a uma falha na rede interna do EC2, que afetou o DNS (Domain Name System) — essencial para roteamento na internet.
Segundo a AWS, não houve ataque cibernético, mas sim um erro operacional que gerou sobrecarga e lentidão no sistema. Após isolar o problema, a empresa levou cerca de nove horas para restaurar os serviços de forma completa.
A AWS prometeu divulgar um relatório pós-incidente detalhado nas próximas semanas.
Lições e estratégias de resiliência
1. Diversificação é essencial
Empresas devem adotar estratégias multi-cloud, distribuindo cargas entre provedores como AWS, Azure e Google Cloud. Isso reduz riscos de paradas completas.
2. Redundância e automação
Rotinas de backup local, testes de failover e monitoramento contínuo (por exemplo, com ferramentas como ThousandEyes) devem ser práticas regulares.
3. Planos de contingência
Treinar equipes para reagir rapidamente a incidentes e manter canais alternativos de comunicação podem economizar milhões em casos de falha.
O papel da AWS na infraestrutura global
Com um domínio de mercado de 30%, a AWS é tanto motor da inovação quanto ponto de vulnerabilidade sistêmica. Cada incidente como esse reacende debates sobre transparência, descentralização e regulamentação da infraestrutura digital.
Em resposta a falhas anteriores, a empresa tem investido em IA para prever incidentes, edge computing para descentralizar cargas e data centers mais sustentáveis. Essas iniciativas indicam um futuro mais resiliente — mas ainda dependente da confiança em poucos players.
Conclusão
A pane de 20 de outubro de 2025 é mais que um problema técnico: é um alerta global sobre a fragilidade da nossa infraestrutura digital. Em um mundo que vive na nuvem, uma falha local pode causar apagões planetários.
Empresas e profissionais precisam aprender com o episódio:
- Diversifique provedores.
- Automatize respostas a falhas.
- Tenha planos de continuidade de negócios.
A nuvem é o coração digital do mundo moderno — e como todo coração, precisa de redundância para continuar batendo.
Agradecimento
Obrigado por acompanhar esta análise da falha na AWS de outubro de 2025.
Esperamos que os insights ajudem você a fortalecer sua infraestrutura e repensar suas dependências digitais.
Compartilhe este conteúdo e contribua para uma internet mais resiliente, ética e sustentável.


